本文的大部分篇幅都将用于介绍我的立场,但是首先我们先要谈谈引入这个数据集的论文《ChestX-ray8: Hospital-scale Chest X-ray Database and Benchmarks on Weakly-Supervised Classification and Localization of Common Thorax Diseases》。我必须指出,自首次发布以来,该数据集的论文和支持文档已经更新过多次——自我开始谈论此事之后至少已经更新过两次。尽管如此,在通读了文档后,我仍然认为我的观点是合适的。
前一阵子有一篇很流行的论文(Understanding deep learning requires rethinking generalization,Zhang et al.)表明了深度学习无法在训练数据中拟合随机标签。我不认为这个结论对研究深度学习模型的人来说是意料之外的,但很多人以此作为反对深度学习的证据。
实际上,我们在寻找可以学习正确地在测试集上输出真实结果的模型,即使所谓的真实结果在视觉上毫无意义。
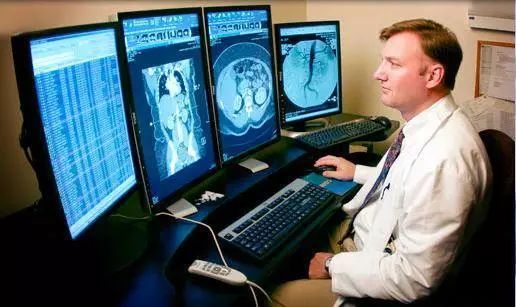
来自 CheXNet 的结果:使用深度学习模型(Rajpurkar and Irvin et al.)在胸透图上进行放射专家级的肺炎检测,在测试集上获得了不错的性能。
现在,一些深度学习拥护者会争辩说,适当的标签噪声是可以接受的,甚至还有好处。
我基本同意 Jeremy 的观点,虽然这依赖于任务类型和噪声类型。随机噪声可以作为不错的正则化项,甚至还可以在某些设置中提升性能(这种技术被称为标签平滑或软标签)。结构化噪声不一样,它添加了完全不同的信号,而模型将尝试学习这些信号。这等价于训练一个模型学习识别肺炎,但其中 10% 的肺炎标签还包括狗的相关标签。




























 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 千斤顶
千斤顶 照妖镜
照妖镜